Fixing bufferbloat on your home network with OpenBSD 6.2 or newer
My home network (which is also my work network) is a standard-issue Comcast cable hookup. In spite of a tolerable 120 megabits down, my experience of daily Internet use is regularly frustrating. Video streams and video chats drop in quality inexplicably. SSH sessions become laggy. Web pages fail to load quickly, and then seem to appear all at once. Even though I should have plenty of bandwidth, the feeling is often one of slowness, waiting, data struggling to get through the pipes.
The reason for this is a phenomenon called "bufferbloat". I'm not going to explain it in detail, there are plenty of good resources to read about it, including the eponymous Bufferbloat.net. Bufferbloat is the result of complex interactions between the software and hardware systems routing traffic around on the Internet. It causes higher latency in networks, even ones with plenty of bandwidth. In a nutshell, software queues in our routers are not letting certain packets through fast enough to ensure that things feel interactive and responsive. Pings, TCP ACKs, SSH connections, are all being held up behind a long line of packets that may not need to be delivered with the same urgency. There's enough bandwidth to process the queue, the trick is to do it more quickly and more fairly.
Fortunately, because bufferbloat is in part a function of how we configure our routers, it's within our ability to solve the problem. But first, we have to diagnose it, and establish a concrete baseline to improve from. The speed test at dslreports.com tests for bufferbloat in addition download and upload speeds, so we'll use that tool to see how we're doing.
First, I run the speed test, and get the following results:
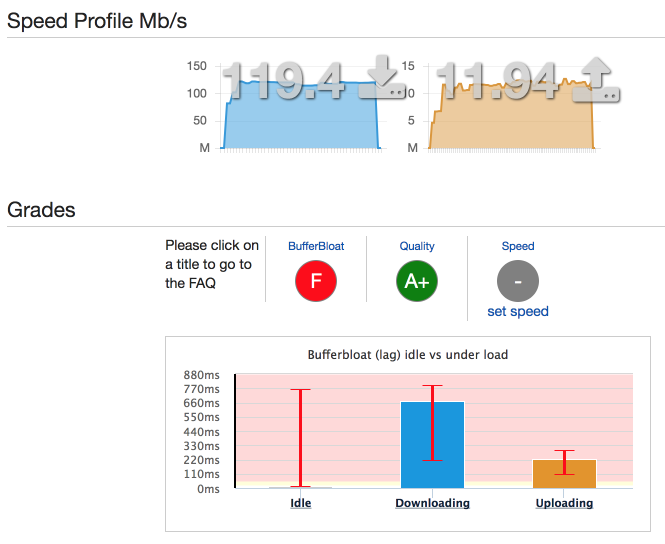
Here you can see the issue starkly: 120 Mbps down and 12 Mbps up yields an "A+" grade (debatable), but we get an "F" for bufferbloat.
We define bufferbloat here as the increased latency of a standard ping while downloading or uploading a large file over ping times while otherwise quiescent.
In our case, our idle latency is 12ms average, a download bloat of about 660ms, and an upload bloat of about 280ms, on average.
The fix is to apply a queue management strategy to our router. Ordinarily, I'd be wary of this. In my experience, QoS administration tends to be fussy and full of unintended consequences. I always felt as if I had cast too broad a net, inadvertantly degrading overall network performance to get slightly better results from one application. And I wasn't sure around what fixed-point I was optimizing. In this case, bufferbloat gives us the measurable target. Administration is made much easier by the appearance of a new algorithm that's easy to apply to network interfaces. It doesn't require much tuning, and you don't need to futz with individual ports or percentages.
Details vary widely by router operating system and administrative UIs. In our case, the router is running OpenBSD. (And if yours isn't, why not? Get a PC Engines board, throw obsd on it, and you have an inexpensive solution with world-class security, efficiency, and performance, that's simple to operate and well-documented.) The OpenBSD way of being a router is through its pf system, which is analogous to Linux's iptables, but much more capable and efficient. Since 6.2, pf has implemented something called "FQ-CoDel", which is an algorithm for scheduling packets fairly and is designed to prevent bufferbloat. It is exposed via the flows option on a queue rule. In principle, all we need to do is add two rules, one to fix uplink bufferbloat and one to fix downlink. Let's see how this goes.
In our /etc/pf.conf, we first add a single line to handle the uplink. This will apply a FQ-CoDel queue to the network interface attached to our WAN link, or the cable modem in our case. The way to think about it is, FQ-CoDel is strategy applied to outbound packets only, as they exit the interface, so even though the WAN interface is duplex up and down, in order to handle the downlink part we'll apply it to the network interface connected to our LAN, which we'll do next.
An important detail. In order for the queue algorithm to do its thing, it needs to know the bandwidth of the outbound link. According to Mike Belopuhov, the implementor of FQ-CoDel in OpenBSD, we need to specify 90-95% of the available bandwidth. Fortunately, we've just measured it.
The line to add to pf.conf to fix bufferbloat on the uplink is (assuming em0 for the WAN interface):
queue outq on em0 flows 1024 bandwidth 11M max 11M qlimit 1024 default
A couple of notes. outq is a label we give, but it's an opaque string to pf. 11M means 11 megabits per second (92% of the uplink bandwidth). qlimit is also specified explicitly, because its default value of 50 is too low for FQ-CoDel. The default keyword is required.
And that's it: we don't need to alter our filtering rules to assign packets to a queue: all outbound packets on this interface are assigned to our new queue.
Now let's reload pf with the config change, and re-run the speed test.
$ doas pfctl -n -f /etc/pf.conf && doas pfctl -f /etc/pf.conf
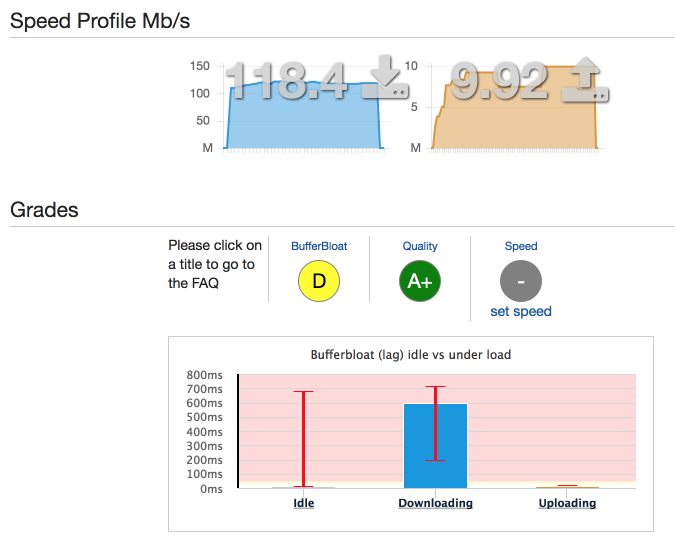
Uplink latency under load is now down to 17ms on average, from 280ms. That's a mere 5ms worse than idle.
(I discount the apparent decrease in uplink bandwidth from this test result. In my experience, dslreports.com could vary by 10-15% in reported bandwidth run-to-run, but over time it converged on 12 Mbps.)
The downlink fix is nearly the same, we just adjust for the name of the interface (the LAN NIC is called em1) and for its 90-95% bandwidth upper bound, which is 110 Mbps.
queue inq on em1 flows 1024 bandwidth 110M max 110M qlimit 1024 default
Reload, re-run:
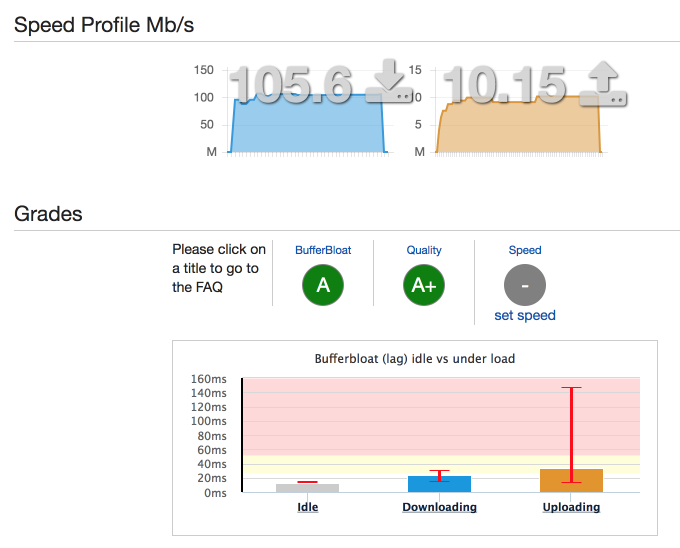
Always nice to get an A. Downlink latency under load is now 24ms, from 660ms.
I haven't elided much, I think that's a pretty decent result for two lines of config. If you want to go further, there's a quantum knob to turn (baseline is your NIC's MTU, but look at what OpenWRT does for guidance), but that's about it.
Post-fix, my observation is that things feel much snappier. Aside from the ping time improvements, I don't have other measurements to cite. But so far, FQ-CoDel seems to have fixed bufferbloat on my network and made for a substantially better experience.